A user account is required in order to edit this wiki, but we've had to disable public user registrations due to spam.
To request an account, ask an autoconfirmed user on Chat (such as one of these permanent autoconfirmed members).
Text input keyboard mode control: Difference between revisions
No edit summary |
No edit summary |
||
| (29 intermediate revisions by 5 users not shown) | |||
| Line 1: | Line 1: | ||
See also http://www.w3.org/Bugs/Public/show_bug.cgi?id=12885 and http://www.w3.org/Bugs/Public/show_bug.cgi?id=12409 . | See also http://www.w3.org/Bugs/Public/show_bug.cgi?id=12885 and http://www.w3.org/Bugs/Public/show_bug.cgi?id=12409 and yet another CSS proposal — [http://lists.w3.org/Archives/Public/www-style/2012Feb/0963 'input-mode']. Mozilla bug: https://bugzilla.mozilla.org/show_bug.cgi?id=746142 | ||
== Existing kinds of keyboards == | == Existing kinds of keyboards == | ||
=== English === | |||
==== iOS ==== | |||
* Telephone number input | |||
* Numeric input | |||
* E-mail address input | |||
* Text input | |||
<img src="http://img.skitch.com/20091107-eu5sgymf9wp6ibdu72hqawthci.jpg"> | |||
<img src="http://img.skitch.com/20091107-m9y8cnuiwe7sh34dtm5u1mcrt2.jpg"> | |||
<img src="http://img.skitch.com/20091107-jqccu6wsgks8t3w4x3k22f4apr.jpg"> | |||
<img src="http://img.skitch.com/20091107-r3p2ejjwb861pwetp1tkq2ccjr.jpg"> | |||
(Images hotlinked from this StackOverflow post: http://stackoverflow.com/questions/773843/iphone-uiwebview-how-to-force-a-numeric-keyboard-is-it-possible ) | |||
==== Android ==== | |||
* Text input with leading capitalisation | * Text input with leading capitalisation | ||
* Numeric input (big 0-9 keys, *, # | * Username / password input? (no capitalisation) | ||
* Text input without capitalisation in a search context (search submission button) | |||
* Numeric input (big 0-9 keys, +, -) | |||
* Telephone number input (big 0-9 keys, *, #) | |||
* URL input (keys for /, "www.", ".com") | * URL input (keys for /, "www.", ".com") | ||
* Email input (keys for @, '-', ".com") | |||
<img src="https://lh5.googleusercontent.com/-tlhqZnBenFU/UAXmYIbPbfI/AAAAAAAASsQ/OkUKYDIINFc/s512/Screenshot_2012-07-17-15-21-21.png"> | |||
<img src="https://lh4.googleusercontent.com/-6ysWEJvC0SM/UAXmXh00VXI/AAAAAAAASsE/5ck8u77pokE/s512/Screenshot_2012-07-17-15-22-26.png"> | |||
<img src="https://lh4.googleusercontent.com/-Kfw79CKG9Hk/UAXmbQW1r9I/AAAAAAAASsw/Nmqgxy4baNo/s512/Screenshot_2012-07-17-15-11-32.png"> | |||
<img src="https://lh4.googleusercontent.com/-e7wbvjJxupI/UAXmaipMmTI/AAAAAAAASso/TkJt6aF2j8w/s512/Screenshot_2012-07-17-15-13-44.png"> | |||
<img src="https://lh3.googleusercontent.com/-Dta3wPbGuos/UAXmZ3b60yI/AAAAAAAASsg/DMIlzBtRPUI/s512/Screenshot_2012-07-17-15-15-01.png"> | |||
<img src="https://lh6.googleusercontent.com/--tbavGIBX30/UAXmZMrQFTI/AAAAAAAASsY/LPuXhDp-VG0/s512/Screenshot_2012-07-17-15-16-47.png"> | |||
<img src="https://lh6.googleusercontent.com/--lhwXP8Qt5s/UAXmXK0oUVI/AAAAAAAASsA/ozve-EtDonE/s512/Screenshot_2012-07-17-15-23-40.png"> | |||
=== Japanese === | |||
==== Android Japanese keyboards==== | |||
Four basic modes: | |||
* kana input [あ] | |||
* roman-alphabet input [A] | |||
* number input [1] | |||
* symbol input [☺ or (^_^)] | |||
Here are three examples of kana mode, using respectively the ATOK, Google, and Samsung IMEs on Android: | |||
<img src="http://people.w3.org/mike/mobile-ime/atok.png" alt="ATOK IME" title="ATOK IME"> | |||
<img src="http://people.w3.org/mike/mobile-ime/google.png" alt="Google IME" title="Google IME"> | |||
<img src="http://people.w3.org/mike/mobile-ime/samsung.png" alt="Samsung IME" title="Samsung IME"> | |||
==== Mac OSX Japanese keyboard switching ==== | |||
Five basic modes: | |||
* Hiragana | |||
* Katakana | |||
* Half-width Katakana | |||
* Half-width Alphanumeric (normal way, as with standard Roman/English keyboard) | |||
* Full-width Alphanumeric (characters are double-width of normal Roman/English characters) | |||
The following screen capture shows the case for keyboard options on a Mac OS X system with two different Japanese IMEs installed. One (called Kotoeri) is the standard built-in Japanese IME that ships with OS X (the options with gray/back icons shown in the menu). The other is Google Japanese IME (the options with blue icons shown in the menu). | |||
== | <img src="http://people.w3.org/mike/mobile-ime/desktop-osx.png" alt="Mac OS X keyboard switcher"> | ||
== Existing APIs == | |||
== | === XForms === | ||
XForms uses a model of modifiers ("startUpper", "predictOff", "digits", etc) and script block names ("simplifiedHanzi", "tagalog", "canadianAboriginal", etc). | |||
Example: http://www.w3.org/TR/xforms/#mode-examples | |||
[[Category:Proposals]] | [[Category:Proposals]] | ||
== Proposed APIs == | |||
=== Gecko === | |||
* 'numeric': 0-9, +, -, comma, dot;<br> | |||
Use case: to have a vkb similar to <input type='number'> without the UI and other stuff that come with <input type='number'>. That could be used for other stuff than numbers for example. | |||
* 'digit': 0-9 only;<br> | |||
Use case: to write digits without being numbers like social security number or credit card number. | |||
* 'uppercase': A-Z only;<br> | |||
Use case: obvious, could even be used on desktop. | |||
* 'lowercase': a-z only;<br> | |||
Use case: obvious, could even be used on desktop. | |||
* 'titlecase': uppercase character for each new word;<br> | |||
Use case: obvious, could even be used on desktop. | |||
* 'autocapitalized': first letter is uppercased;<br> | |||
Use case: obvious, could even be used on desktop. Also, that would be a parity feature for iOS autocapitalized attribute. | |||
Except 'number' it's not obvious that we should have input modes similar to input types (like email, tel, url). Actually, we could even discuss the use case of 'number'.<br> | |||
This is intended to be a small set of quite obvious input modes. Some other might be useful. | |||
=== Ian Hickson === | |||
These are arranged in a tree shape. A user agent only has to support one input method, the default input method, which is the root of the tree. It may support any of the others listed; if one is requested by an author, then the user agent should use it, or the nearest ancestor in the tree that it supports (i.e. fallback up the tree). | |||
* User Default Input Method | |||
** Latin text verbatim (usernames, passwords) | |||
*** Latin text with prediction and capitalisation (for communication with other humans: chat, e-mail subject or body, etc) | |||
**** Latin text with prediction but no capitalisation (for communication with computers: search, programming, etc) | |||
***** Full-width latin text with prediction and capitalisation (for communication with other humans in an otherwise CJK context) | |||
** Hiragana text, with support for upconversion to Kanji (Japanese input) | |||
*** Katakana text, with support for upconversion to Kanji (Japanese input) | |||
**** Half-width katakana text (Japenese input) | |||
** Numeric input (e.g. times; includes key for thousands separator and - key) | |||
*** Telephone number input (includes * and # keys) | |||
** E-mail address input (includes @ key) | |||
** Web address input (includes / key) | |||
Latest revision as of 21:11, 20 July 2012
See also http://www.w3.org/Bugs/Public/show_bug.cgi?id=12885 and http://www.w3.org/Bugs/Public/show_bug.cgi?id=12409 and yet another CSS proposal — 'input-mode'. Mozilla bug: https://bugzilla.mozilla.org/show_bug.cgi?id=746142
Existing kinds of keyboards
English
iOS
- Telephone number input
- Numeric input
- E-mail address input
- Text input
<img src="http://img.skitch.com/20091107-eu5sgymf9wp6ibdu72hqawthci.jpg"> <img src="http://img.skitch.com/20091107-m9y8cnuiwe7sh34dtm5u1mcrt2.jpg"> <img src="http://img.skitch.com/20091107-jqccu6wsgks8t3w4x3k22f4apr.jpg"> <img src="http://img.skitch.com/20091107-r3p2ejjwb861pwetp1tkq2ccjr.jpg">
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(Images hotlinked from this StackOverflow post: http://stackoverflow.com/questions/773843/iphone-uiwebview-how-to-force-a-numeric-keyboard-is-it-possible )
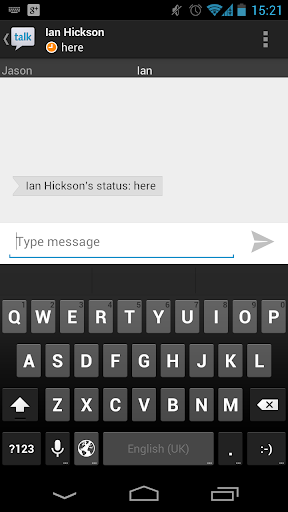
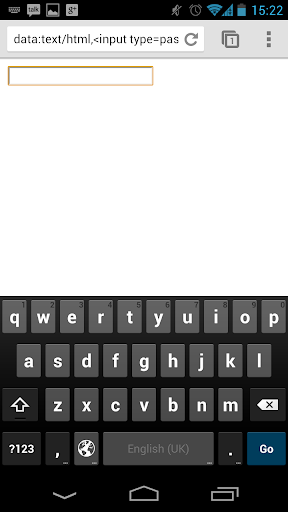
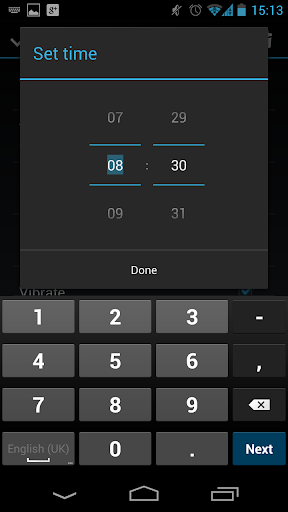
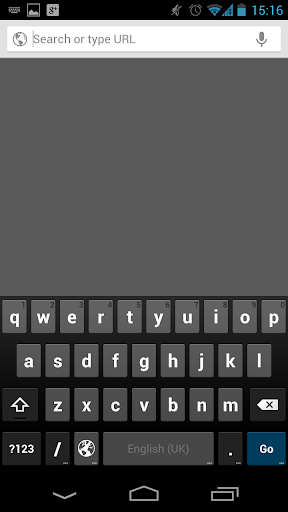
Android
- Text input with leading capitalisation
- Username / password input? (no capitalisation)
- Text input without capitalisation in a search context (search submission button)
- Numeric input (big 0-9 keys, +, -)
- Telephone number input (big 0-9 keys, *, #)
- URL input (keys for /, "www.", ".com")
- Email input (keys for @, '-', ".com")
<img src="https://lh5.googleusercontent.com/-tlhqZnBenFU/UAXmYIbPbfI/AAAAAAAASsQ/OkUKYDIINFc/s512/Screenshot_2012-07-17-15-21-21.png"> <img src="https://lh4.googleusercontent.com/-6ysWEJvC0SM/UAXmXh00VXI/AAAAAAAASsE/5ck8u77pokE/s512/Screenshot_2012-07-17-15-22-26.png"> <img src="https://lh4.googleusercontent.com/-Kfw79CKG9Hk/UAXmbQW1r9I/AAAAAAAASsw/Nmqgxy4baNo/s512/Screenshot_2012-07-17-15-11-32.png"> <img src="https://lh4.googleusercontent.com/-e7wbvjJxupI/UAXmaipMmTI/AAAAAAAASso/TkJt6aF2j8w/s512/Screenshot_2012-07-17-15-13-44.png"> <img src="https://lh3.googleusercontent.com/-Dta3wPbGuos/UAXmZ3b60yI/AAAAAAAASsg/DMIlzBtRPUI/s512/Screenshot_2012-07-17-15-15-01.png"> <img src="https://lh6.googleusercontent.com/--tbavGIBX30/UAXmZMrQFTI/AAAAAAAASsY/LPuXhDp-VG0/s512/Screenshot_2012-07-17-15-16-47.png"> <img src="https://lh6.googleusercontent.com/--lhwXP8Qt5s/UAXmXK0oUVI/AAAAAAAASsA/ozve-EtDonE/s512/Screenshot_2012-07-17-15-23-40.png">
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Japanese
Android Japanese keyboards
Four basic modes:
- kana input [あ]
- roman-alphabet input [A]
- number input [1]
- symbol input [☺ or (^_^)]
Here are three examples of kana mode, using respectively the ATOK, Google, and Samsung IMEs on Android:
<img src="http://people.w3.org/mike/mobile-ime/atok.png" alt="ATOK IME" title="ATOK IME"> <img src="http://people.w3.org/mike/mobile-ime/google.png" alt="Google IME" title="Google IME"> <img src="http://people.w3.org/mike/mobile-ime/samsung.png" alt="Samsung IME" title="Samsung IME">
{kind=link}
{kind=link}
{kind=link}
Mac OSX Japanese keyboard switching
Five basic modes:
- Hiragana
- Katakana
- Half-width Katakana
- Half-width Alphanumeric (normal way, as with standard Roman/English keyboard)
- Full-width Alphanumeric (characters are double-width of normal Roman/English characters)
The following screen capture shows the case for keyboard options on a Mac OS X system with two different Japanese IMEs installed. One (called Kotoeri) is the standard built-in Japanese IME that ships with OS X (the options with gray/back icons shown in the menu). The other is Google Japanese IME (the options with blue icons shown in the menu).
<img src="http://people.w3.org/mike/mobile-ime/desktop-osx.png" alt="Mac OS X keyboard switcher">
{kind=link}
Existing APIs
XForms
XForms uses a model of modifiers ("startUpper", "predictOff", "digits", etc) and script block names ("simplifiedHanzi", "tagalog", "canadianAboriginal", etc).
Example: http://www.w3.org/TR/xforms/#mode-examples
Proposed APIs
Gecko
- 'numeric': 0-9, +, -, comma, dot;
Use case: to have a vkb similar to <input type='number'> without the UI and other stuff that come with <input type='number'>. That could be used for other stuff than numbers for example.
- 'digit': 0-9 only;
Use case: to write digits without being numbers like social security number or credit card number.
- 'uppercase': A-Z only;
Use case: obvious, could even be used on desktop.
- 'lowercase': a-z only;
Use case: obvious, could even be used on desktop.
- 'titlecase': uppercase character for each new word;
Use case: obvious, could even be used on desktop.
- 'autocapitalized': first letter is uppercased;
Use case: obvious, could even be used on desktop. Also, that would be a parity feature for iOS autocapitalized attribute.
Except 'number' it's not obvious that we should have input modes similar to input types (like email, tel, url). Actually, we could even discuss the use case of 'number'.
This is intended to be a small set of quite obvious input modes. Some other might be useful.
Ian Hickson
These are arranged in a tree shape. A user agent only has to support one input method, the default input method, which is the root of the tree. It may support any of the others listed; if one is requested by an author, then the user agent should use it, or the nearest ancestor in the tree that it supports (i.e. fallback up the tree).
- User Default Input Method
- Latin text verbatim (usernames, passwords)
- Latin text with prediction and capitalisation (for communication with other humans: chat, e-mail subject or body, etc)
- Latin text with prediction but no capitalisation (for communication with computers: search, programming, etc)
- Full-width latin text with prediction and capitalisation (for communication with other humans in an otherwise CJK context)
- Latin text with prediction but no capitalisation (for communication with computers: search, programming, etc)
- Latin text with prediction and capitalisation (for communication with other humans: chat, e-mail subject or body, etc)
- Hiragana text, with support for upconversion to Kanji (Japanese input)
- Katakana text, with support for upconversion to Kanji (Japanese input)
- Half-width katakana text (Japenese input)
- Katakana text, with support for upconversion to Kanji (Japanese input)
- Numeric input (e.g. times; includes key for thousands separator and - key)
- Telephone number input (includes * and # keys)
- E-mail address input (includes @ key)
- Web address input (includes / key)
- Latin text verbatim (usernames, passwords)